Efficient Attention: Attention with Linear Complexities
Efficient Attention: attention with Linear Complexities is a work by myself and colleagues at SenseTime. We proposed a simple but effective method to decrease the computational and memory complexities of the attention mechanism from quadratic to linear, without loss of accuracy. This blog post will introduce the method and major results of the paper.
Motivation
The Attention Mechanism
The attention mechanism is a mechanism in neural networks that allows direct connection between each pair of positions in the input. Its core advantage over recurrence and convolution is its ability to modeling long-range dependency. Following is a diagram depicting a typical attention module.
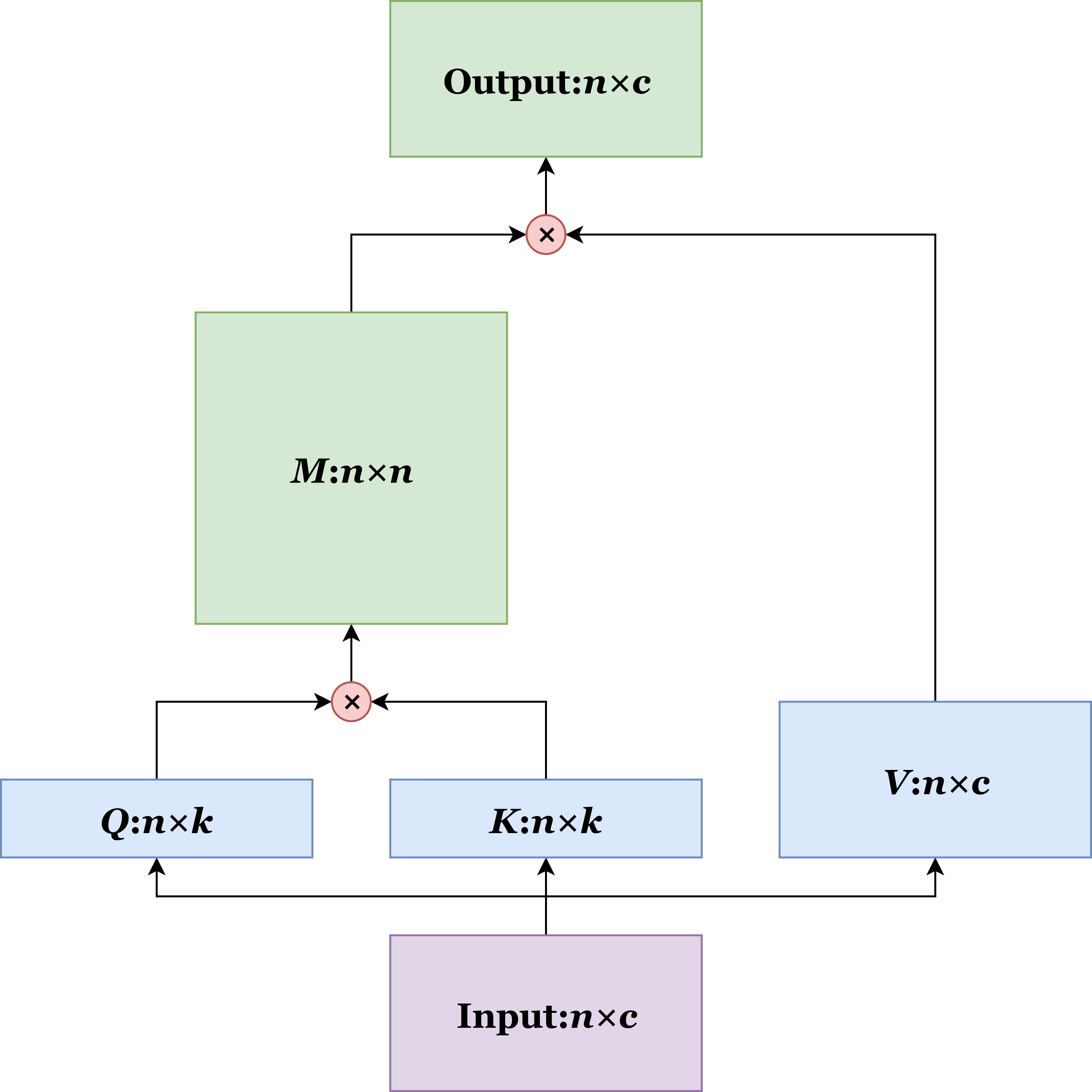
In this diagram, n represents the number of positions in the input, k and c represent the dimensionalities of the keys and the input, K, Q, V, and M represent the keys, the queries, the values, and the attention masks, respectively. This blog post will assume knowledge of the conventional attention mechanism. For more information on this topic, please refer to this blog post by Jay Alammar from Udacity.
Drawback of Attention
Despite its excellent ability for long-range dependency modeling, attention has a serious drawback. As you can see in the figure above, the intermediate result M’s shape is n*n. This means 1) its memory complexity is quadratic; 2) to generate the quadratically many elements, the computational complexity is also quadratic. Consequently, the memory and computational complexities of the entire attention module are quadratic.
This is a critical drawback. As computer scientists, we understand that a quadratic algorithm is much slower than a linear one on large inputs. And the gap grows rapidly as the input gets larger. This effectively forbids the application of attention on large inputs, like high-definition images, long sequences, and large videos. However, these inputs are important in various tasks, like object detection, instance segmentation, stereo vision, and video classification. Therefore, to democratize the attention mechanism to many more fields, it is critical to address its quadratic complexities.
Our Method
A Closer Look at the Architecture Diagram
To learn how to solve the issue of quadratic complexities, let’s take a closer look at the architecture diagram of the attention module. The most resource-consuming and the only quadratically complex part of the module is the attention masks M of size n*n.
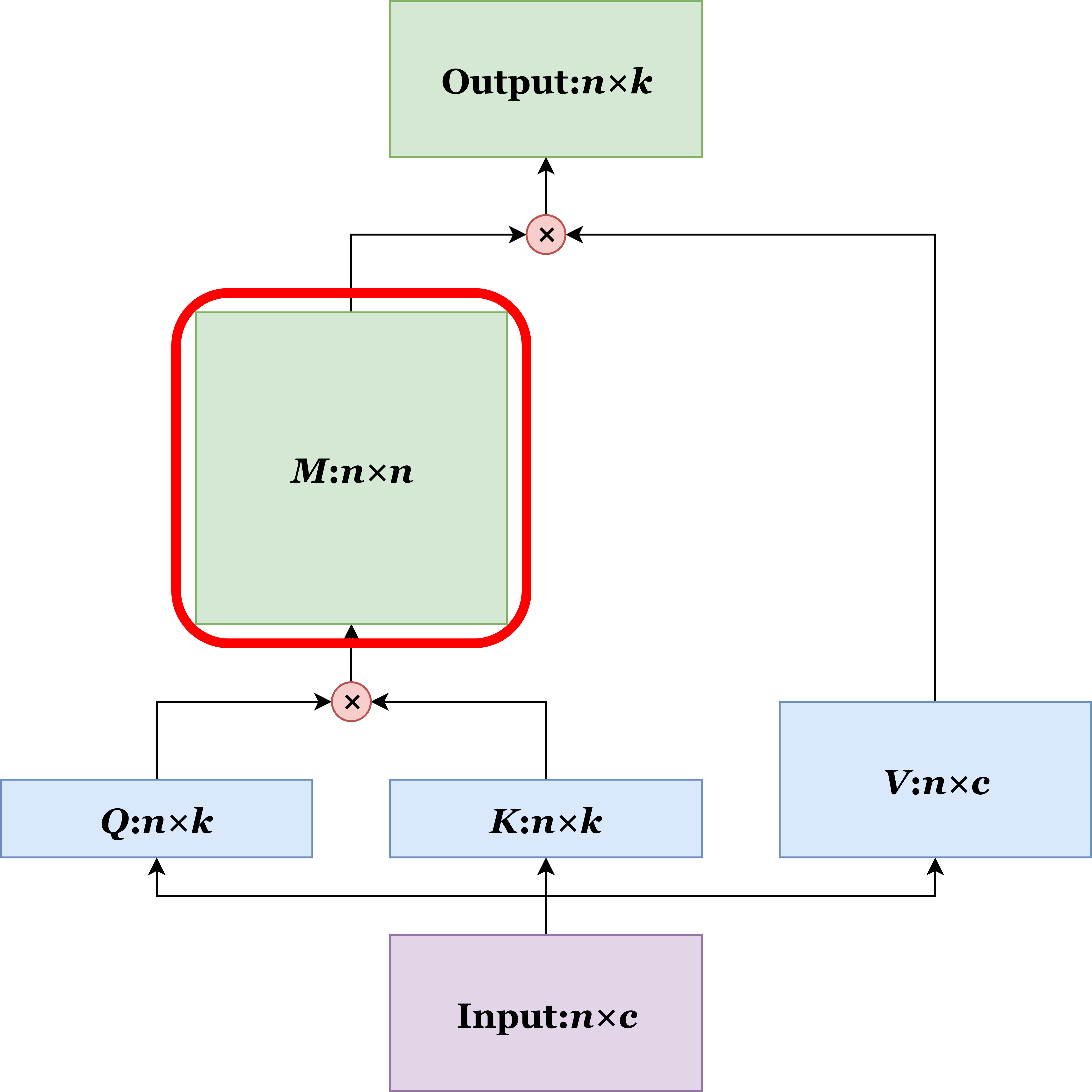
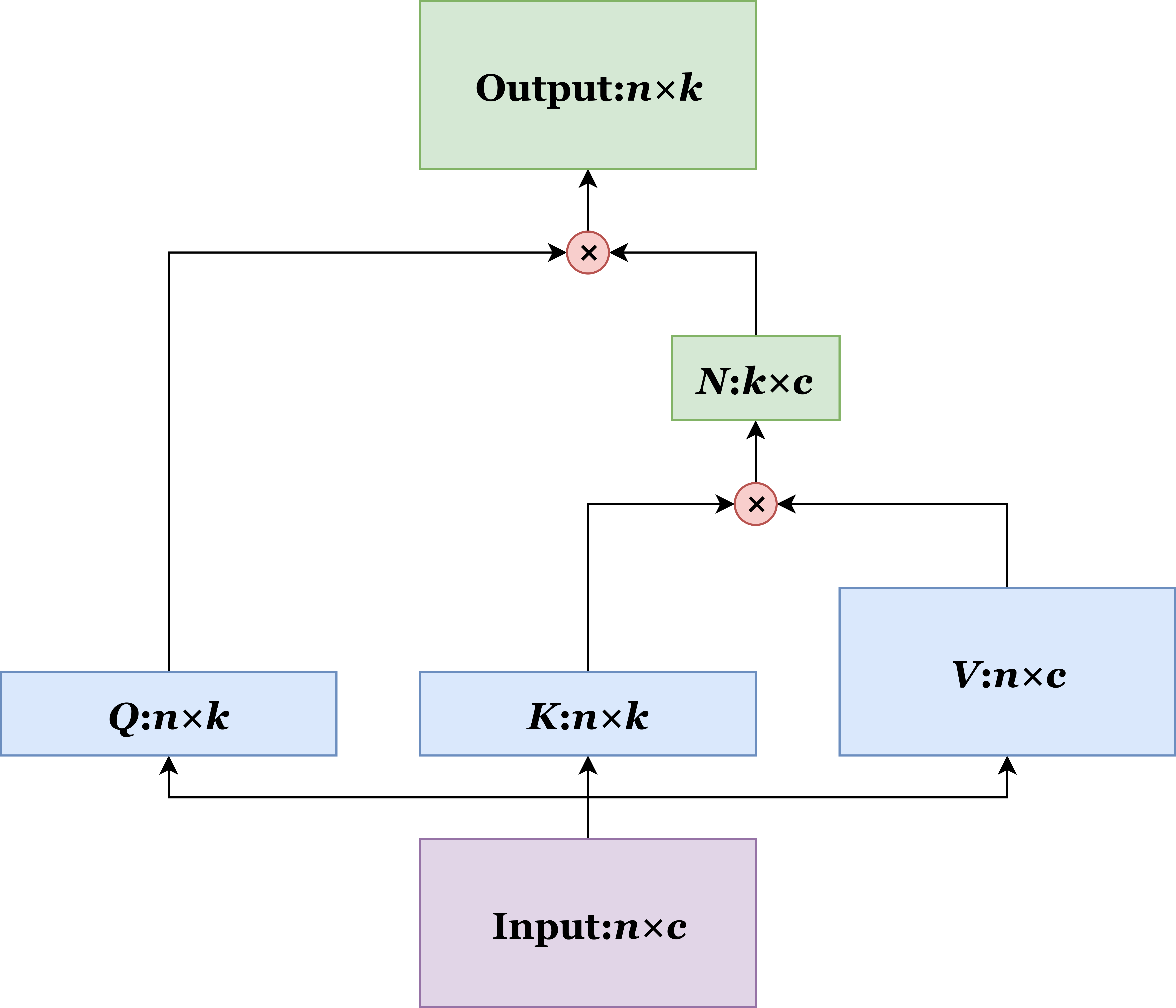
However, if we more closely examine the diagram, we can see that M is surrounded by two consecutive matrix multiplications, as illustrated below. Now, recall your freshman-year linear algebra course. Matrix multiplication is associative, which means if there are multiple consecutive matrix multiplications, you can choose whatever order to calculate. Therefore, what we can do is to simply swap the order of the two multiplications. Aha! This is the magic.
After the swapping, the size of the intermediate result changes from n*n to k*c. Since both k and c are constants under our control, the resultant memory complexity is O(1). After some calculation, you can get the computational complexity, which is O(n). This is the efficient attention mechanism.
What about Normalization?
However, the analysis above is only for the vanilla version of attention. In practice, we often apply normalization to the attention masks to stablized training. Will the addition of normalization mess up the analysis? Let’s look into this question with two dominant approaches for attention normalization, scaling normalization and softmax normalization.
For scaling normalization, the question is trivial. Since scaling normalization is merely dividing the attention masks M by a scalar that depends on k (sqrt(k), to be precise), we can do the exact same thing on N, and the effect remains unchanged.
The situation is slightly more complicated for softmax normalization. Since softmax is nonlinear, we cannot simply move the operation to N or anothre matrix. However, we can approximate its effect with two seperate softmax operations on C and B, respectively. The softmax on C is performed along its channel dimension, while the one on B is along the spatial dimension. After these operations, if we multiply C and B, their product will satisfy the same essential property as M that each row in it sums up to 1. Despite these operations are not exactly equivalent to the original, we have conducted empirical experiments to verify that the approximation doesn’t cause any degradation in performance.
Empirical Validation
Okay. So now we have finished presenting the efficient attention module itself. Let’s have a look at how it performs in the real world. We picked 4 tasks to validate its performance: object detection, instance segmentation, image classification, and stereo depth estimation.
Object Detection and Instance Segmentation
We mainly conducted comparative and ablative studies on these two tasks. For these tasks, we use the standard MS-COCO 2017 dataset.
| Method | Box AP | Mask AP |
|---|---|---|
| None | NaN | NaN |
| Scaling | 40.2 | 35.9 |
| Softmax | 40.2 | 36.0 |
We first compared the two proposed attention normalization methods. You can see that the two methods perform almost identically. This shows that the effectiveness of the efficient attention module lies in its essential formulation, rather than any specific implementation.
| Number of modules | Box AP | Mask AP |
|---|---|---|
| 1 | 40.2 | 36.0 |
| 5 | 40.6 | 36.1 |
| 7 | 41.2 | 36.7 |
After that, we experimented with adding not just one, but multiple efficient attention modules to different parts of the network. (For details on where we inserted the modules and hyperparameter settings, refer to the paper.) In this table, the trend is that the more you insert, the more (performance) you get. This results shows that the performance advantage provided by the efficient attention module can scale with more of the module included in the network.
| Backbone | Baseline AP | With EA modules |
|---|---|---|
| ResNet-50 | 39.4/35.1 | 41.2/36.7 |
| ResNet-101 | 41.3/36.6 | 43.1/37.9 |
| ResNeXt-101 | 43.5/38.5 | 44.9/39.5 |
Next, we explore the effect of efficient attention on different backbone networks. The table shows that efficient attention is consistently effective on a diversity of backbones. It provides a considerable gain (+1.4 box AP and +1.0 mask AP) even on a highly competitive, ResNeXt-101 baseline.
| Number of modules | Efficient attention (box/mask) | Conventional attention (box/mask) |
|---|---|---|
| 1 | 40.2/36.0 | 40.3/35.9 |
| 5 | 40.6/36.1 | OOM |
| 7 | 41.2/36.7 | OOM |
Then, we compared the effectiveness of efficient attention against conventional attention. As you can see, when inserting the same number of modules, efficient and conventional attention have very similar performance. When adding more modules, efficient attention’s performance increases steadily. However, the conventional modules quickly experienced out-of-memory errors and wasn’t able to enjoy the benefit brought by incorporating more modules into the network.
| Method | Backbone | AP |
|---|---|---|
| TDM Faster R-CNN | Inception-ResNet-v2 | 36.8 |
| Mask R-CNN | ResNeXt-101 | 39.8 |
| Soft-NMS | Aligned-Inception-ResNet | 40.9 |
| Lighthead R-CNN | ResNet-101 | 41.5 |
| Fitness-NMS | ResNet-101 | 41.8 |
| EA Mask R-CNN | ResNet-101 | 43.1 |
| EA Mask R-CNN | ResNeXt-101 | 45.9 |
Finally, we contrasted efficient attention-augmented detectors and instance segmenters against state-of-the-art published methods. EA Mask R-CNN has set a new state-of-the-art on MS-COCO 2017 object detection and instance segmentation.
Stereo Depth Estimation and Image Classification
To prove the generalizability of efficient attention, we also tried it on two other important tasks, stereo depth estimation and image classification.
Stereo Depth Estimation
For stereo depth estimation, we used a PSMNet with optimized hyperparameters as the baseline. The dataset used was Scene Flow. We only experimented with adding a single DA module.
| Model | EPE |
|---|---|
| iResNet-i2 | 1.40 |
| PSMNet | 1.09 |
| EdgeStereo | 1.12 |
| CSPN | 0.78 |
| EA-PSMNet | 0.48 |
As the table shows, EA-PSMNet has set a record of end-point error (EPE) on the Scene Flow dataset by a large margin.
Image Classification
For image classification, we used ResNet-50 as our baseline and tested on the ImageNet dataset.
| Number of modules | Top-1 accuracy (%) | Improvement |
|---|---|---|
| 0 | 76.052 | 0.000 |
| 1 | 76.932 | 0.880 |
| 2 | 77.312 | 1.260 |
As in the table, the incorporation of a couple of efficient attention modules substantially improves the performance of a ResNet-50.
Why It Matters?
Efficient attention dramatically reduces the resource needs of the attention mechanism. It offers three advantages over conventional formulations:
- With the same network architecture, efficient attention saves resources.
- Under the same resource budget, efficient attention offers better performance.
- In fields where the application of attention wasn’t possible, efficient attention enables the possibilities.
Efficient attention has the potential to democratize attention to many more applications and offers a huge amount of extra freedom in network architecture design.